マンガキャラクタにおける手足を含めた姿勢推定の検討

迎山研究室 野寺由規
昨今、機械学習を活用した技術は様々な分野で利用されている。そんな機械学習を応用した画像認識分野の対象の1 つにマンガ作品がある。マンガに登場するキャラクターは多様な姿勢で描かれており、姿勢に関する研究の中に姿勢推定というものが存在する。人間の関節(キーポイント)を特定する姿勢推定をマンガに適用した研究ではキーポイントが手首・足首までの少ない個数で行われたものであった。 つまり、手足の指まで含めた姿勢推定を行うことができていない。よって、先行研究をもとにマンガキャラクターにおけるk\姿勢推定のさらなる精度向上を目指した。
マンガキャラクタに対する手足を含めた姿勢推定を行うにあたって、訓練データの作成を行った。マンガ画像を訓練データとする場合、マンガ画像に手作業でキーポイントを打つ必要があり、コストがかかりすぎる。よって、代案としてすでに手足まで含めたキーポイントデータが存在する実写画像を線画に変換し、コマ枠・フキダシ・オノマトペを合成したマンガ調画像にキーポイントデータを流用する方法を採用した。こうして作成した訓練データを用いて新たな学習モデルを作成した。また、姿勢推定を適用するマンガのコマ画像を見開き1ページのマンガ画像から切り抜く作業と姿勢推定に必要なアノテーションデータの作成も行った。
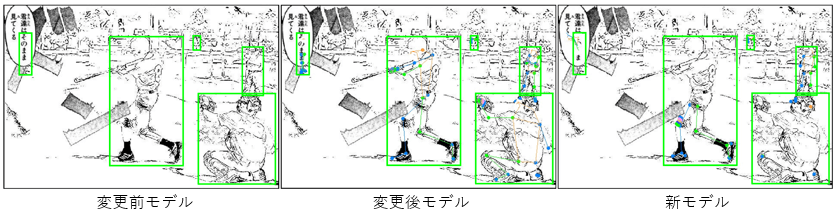
実験としてマンガ調画像に対する姿勢推定とその精度算出を3つの学習モデルで行った。実写画像かつ、17個のキーポイントで学習したモデル(変更前モデル)、マンガ調画像かつ、手足と顔を含む133個のキーポイントで学習したモデル(変更後モデル)、実写画像かつ、手足と顔を含む133個のキーポイントで学習したモデル(新モデル)の3つである。さらに、マンガ画像に対してもこの3つの学習モデルで姿勢推定を行った。
マンガ調画像に対する実験結果は変更後モデル、新モデル、変更前モデルの順で精度が高かった。このことから、手足を含まない学習モデルよりも手足を含む学習モデルを用いたほうが手足を含めた姿勢推定の精度は向上する。加えて、実写画像の学習モデルよりもマンガ調画像の学習モデルのほうがマンガ調画像の姿勢推定においては精度が向上することが分かった。
実際のマンガ画像に対する姿勢推定では新モデル、変更後モデル、変更前モデルの順でキーポイントの検出数が多かった。マンガ画像には精度評価に必要な正解データがないため精度の算出は行っていない。
また、姿勢推定を行う範囲をあらかじめ指定するトップダウン型の手法を用いることでフキダシやオノマトペの誤検出は減らせると思われる。